What is NVMe over Fabrics?
Evolvement of NVMe interface protocol is the boon to SSD based storage arrays. It further powered SSDs to obtain high performance and reduced latency for accessing data. Benefits further extended by NVMe over Fabrics network protocol which brings NVMe feature retained over network fabric while accessing the storage array remotely. Let’s understand how.
While leveraging NVMe protocol with storage arrays consists of high-speed NAND and SSDs, a latency was experienced when NVMe based storage arrays access through shared storage or storage area networks (SAN). In SAN, data should be transferred between host (initiator) and the NVMe-enabled storage array (target) over Ethernet, RDMA technologies (iWARP/RoCE), or Fibre Channel. Latency caused due to a translation of SCSI commands into NVMe commands in process of transportation of data. To address this bottleneck, NVM express introduced NVMe over Fabrics protocol to get replaced with iSCSI as storage networking protocol. With this, NVMe benefits taken onto network fabrics in SAN kind of architecture to have a complete end to end NVMe based storage model which is highly efficient for new age workloads. NVMe-oF supports all available network fabrics technologies like RDMA (RoCE, iWARP), Fibre Channel (FC-NVMe), Infiniband, Future Fabrics, and Intel Omni-Path architecture.

NVMe over Fabrics and OpenStack
As we know that OpenStack consists of a library of open source projects for the centralized management of data center operations. OpenStack provides an ideal environment to implement efficient NVMe based storage model for high throughput. OpenStack Nova and Cinder are components used in proposed NVMe-oF with OpenStack solution. This consists of creation and integration of Cinder NVME-oF target driver along with OpenStack Nova.
OpenStack Cinder is a block storage service project for OpenStack deployments mainly used to create services which provide persistent storage to cloud-based applications. It provides APIs to users to access storage resources without disclosing storage location information.
OpenStack Nova is component within OpenStack which helps is providing on-demand access to compute resources like virtual machines, containers, and bare metal servers. In NVMe-oF with OpenStack solutions Nova in attaching NVMe volumes to VMs.
A support of NVMe-oF in OpenStack is available from “Rocky” release. A proposed solution requires RDMA NICs and supports kernel initiator and kernel target.
NVMe-oF Targets Supported
Based on the proposed solution above we get 2 choices to implement NVMe-oF with OpenStack. First with a Kernel NVMe-oF target driver which is supported as of OpenStack “R” release. The second implementation is Intel’s SPDK based NVMe-oF implementation containing SPDK NVMe-oF target driver and SPDK LOLVOL (Logical Volume Manager) backend which is anticipated in OpenStack S release.
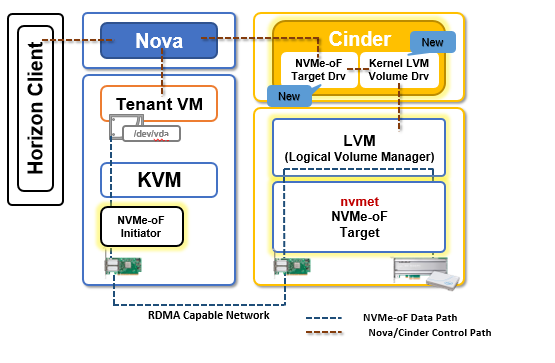
Kernel NVMe-oF Target (Supported as of OpenStack “R” release)
Here is the implementation consist of support for kernel target and kernel initiator. But kernel based NVMe-oF target implementation has limitations in terms of number of IOPs per CPU core. Also, kernel-based NVMe-oF suffers a latency issue due to CPU interrupts, many systems calls to read data, and time take to transfer data between threads.
SPDK NVMe-oF Target (Anticipated in Openstack “S” release)
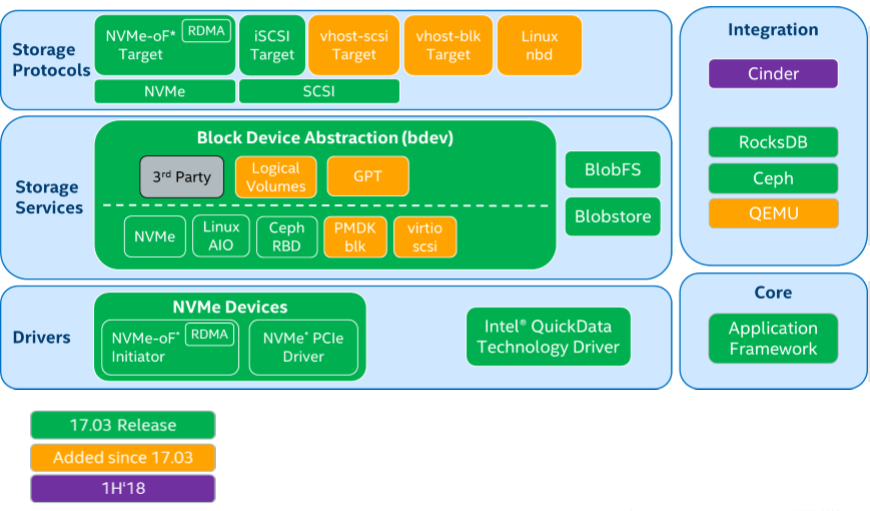
Why SPDK?
SPDK architecture achieved high performance for NVMe-oF with OpenStack by moving all necessary application drivers to userspaces (apart from the kernel) and enables operation in polled mode rather interrupt mode and lockless (avoiding the use of CPU cycles synchronizing data between threads) processing.
Let’s understand what it means.
In SPDK implementation, storage drivers which are utilized for storage operations like storing, updating, deleting data are isolated from kernel space where general purpose computing processes run. This isolation of storage drivers from kernel saves an amount of time required for processing in the kernel and enables CPU cycles to spend more time for execution of storage drivers at user space. This avoids interruption and locking of storage driver with other general purpose computing drivers in kernel space.
In typical I/O model, application request read/write data access and waits till I/O cycle to complete. In polled mode, once application places a request for data access it goes at other execution and comes back after a defined interval to check completion of an earlier request. This reduces latency and process overheads and further improves the efficiency of I/O operations.
By summarizing,
SPDK specially designed to extract performance from non-volatile media, containing tools and libraries for scalable and efficient storage applications utilized userspace, and polled mode components to enable millions IO/s per core. SPDK architecture is open source BSD licensed blocks optimized for bringing out high throughput from the latest generation of CPUs and SSDs.
Why SPDK NVMe-oF Target?
As per performance benchmarking report of NVMe-oF using SPDK, it has been seen that
-
- Throughput scales up and latency decreases almost linearly with the scaling of SPDK NVMe-oF target and initiator I/O cores.
- SPDK NVMe-oF target performed up to 7.3x better w.r.t IOPS/core than Linux Kernel NVMe-oF target while running 4K 100% random write workload with increasing number of connections (16) per NVMe-oF subsystem.
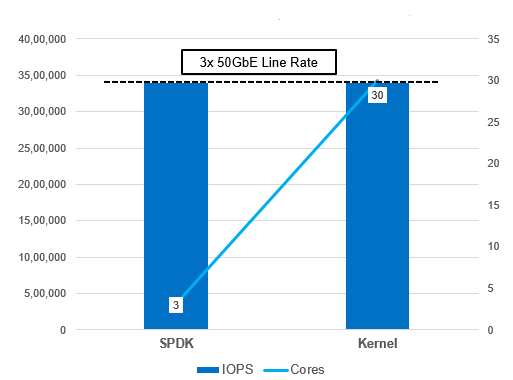
- SPDK NVMe-oF initiator is 3x 50GbE faster than Kernel NVMe-oF initiator with null bdev based backend.
- SPDK reduces NVMe-oF software overhead up to 10x.

Fig – SPDK vs. Kernel NVMe-oF I/O Efficiency NVMe over Fabrics Target Features Realized Benefit Utilizes NVM Express* (NVMe) Polled Mode Driver Reduced overhead per NVMe I/O RDMA Queue Pair Polling No interrupt overhead Connections pinned to CPU cores No synchronization overhead
- SPDK saturates 8 NVMe SSDs with a single CPU core
SPDK NVMe-oF implementation
This is the first implementation of NVMe-oF integrating with OpenStack (Cinder and Nova) which leverages NVMe-oF target driver and SPDK LVOL (Logical Volume Manager) based SDS storage backend. This provides a high-performance alternative to kernel LVM and kernel NVMe-oF target.
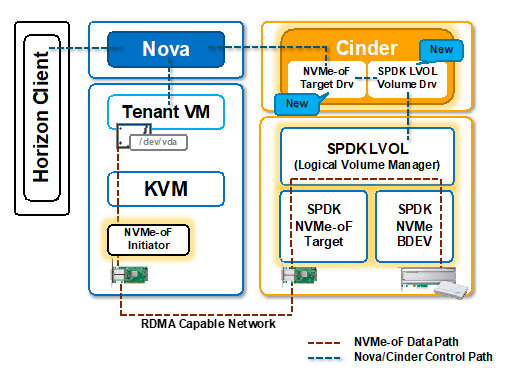
The implementation is demonstrated at OpenStack Summit 2018 Vancouver. You can watch the demonstration video here.
If compared with Kernel-based implementation, SPDK reduces NVMe-oF software overheads and yields high throughput and performance. Let’s see how this will be added to upcoming OpenStack “S” release.
This article is based on a session at OpenStack Summit 2018 Vancouver – OpenStack and NVMe-over-Fabrics – Network connected SSDs with local performance. The session was presented by Tushar Gohad (Intel), Moshe Levi (Mellanox) and Ivan Kolodyazhny (Mirantis).
[Tweet “OpenStack and NVMe-over-Fabrics – Getting High Performance for Network Connected SSDs ~ via @CalsoftInc”]





